Caractères
Les chaînes de caractères - Python (vidéo)⚓︎
Vidéo de David Latouche (06:09)

Représentation des caractères⚓︎
Codage numérique du texte (Eduscol : ressource ISN)⚓︎
Fichier PDF

Encodage des caractères en UTF-8 dans les pages web⚓︎
Problème
Bien que le code UTF-8 du « e accent aigu » (e acute), de code Unicode U+E9 (233), soit 0xC3A9 :
- Avec « &\({}\)eacute » (entité HTML), le navigateur va afficher « é ».
- Avec « &\({}\)#233 » (code décimal), le navigateur va afficher « é ».
- Avec « &\({}\)#xE9 » (code hexadécimal), le navigateur va afficher « é ».
- Avec « &\({}\)#xC3A9 » (code UTF-8), le navigateur va afficher « 쎩 ».
En fait, HTML affiche le caractère UTF-8 쎩 correspondant à la syllabe coréenne Hangul qui a le code Unicode \xC3A9 :
- « &\({}\)#233; » (é) et « &\({}\)#xE9; » (é) représentent l'entier 233 aux formats décimal et hexadécimal, respectivement. 233 est la valeur numérique du point de code Unicode U+00E9 LATIN SMALL LETTER E WITH ACUTE, qui est codée en octets UTF-8 sous la forme de deux octets 0xC3 0xA9.
- « &\({}\)#xc3a9; » (쎩) représente l'entier 50089 au format hexadécimal (0xC3A9). 50089 est la valeur numérique du code Unicode U+C3A9 HANGUL SYLLABLE SSYEOLG, qui est codé en UTF-8 sous la forme de trois octets 0xEC 0x8E 0xA9.
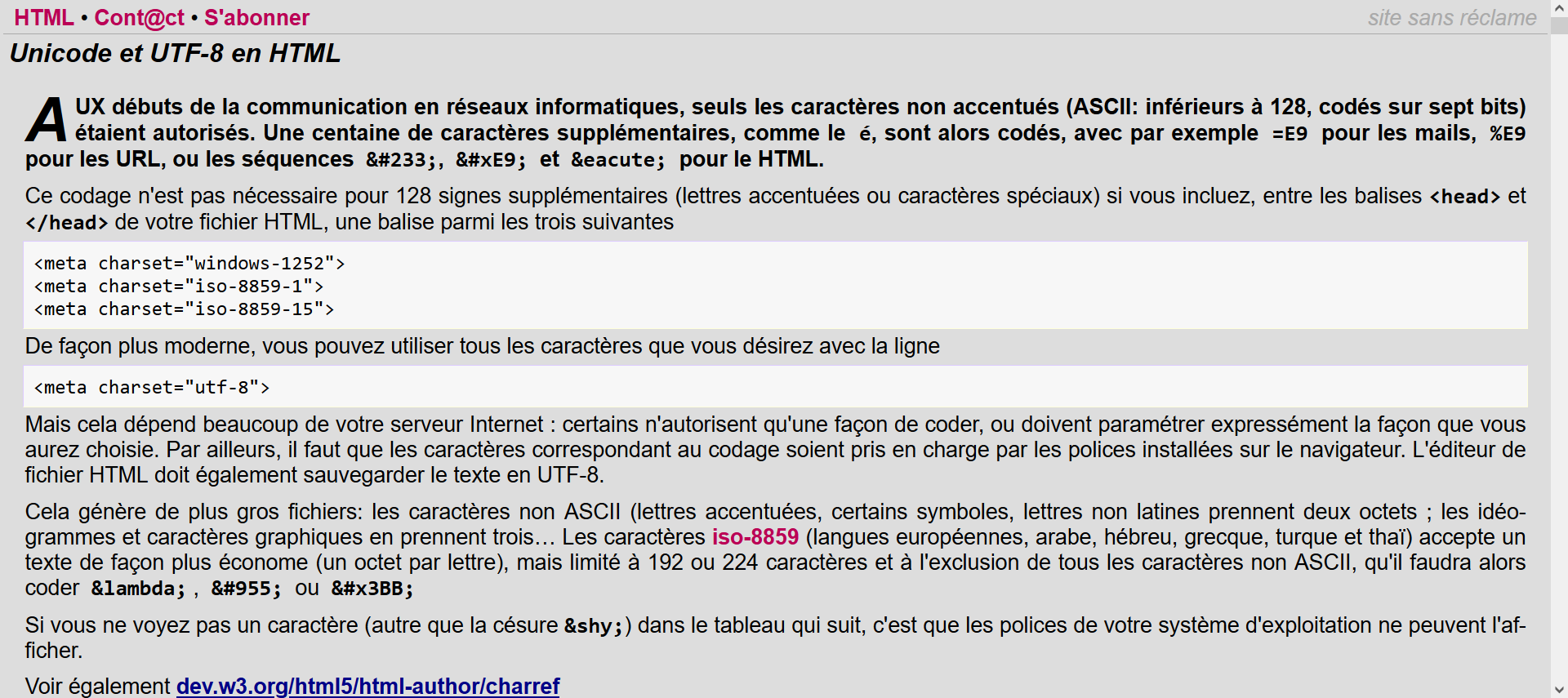
Codes Unicode et UTF-8 des caractères en HTML⚓︎
Site à consulter
Exercices sur les chaînes de caractères en Python⚓︎
Exercice 1 : caractères et codes ASCII